

Как добыть уникальный контент из вебархива
![]()
Всем привет =) Сегодня хочется вам рассказать, как можно совершенно бесплатно добывать уникальный контент для своих проектов! Сразу скажу, этот способ я подглядел на одном из форумов, но немного модифицировал его под себя, чем и хочу поделиться с читателями.
Для начала пару слов о WebArchive. Это глобальный архив интернет сайтов. Боты вебархива периодически обходят глобальную паутину и сохраняют на свои сервера все что смогли найти. Потом это все хранится для потомков 😉
Адрес ВебАрхива — http://archive.org/web/ На главной странице, на момент написания статьи, написано — 452 billion web pages saved over time. По-русски говоря, 452 миллиарда страниц закачал себе этот сервис. Этим мы и будем пользоваться.
Суть этого метода проста — мы ищем уже неработающие сайты, которые были закачаны вебархивом и стараемся найти там уникальные статьи, которые уже давно не в индексе поисковых систем.
Итак, поехали, первый способ, прочитанный на форуме:
Идем сюда — nic.ru
Скачиваем список освобождающихся доменов в зоне .ru Можно брать и другие зоны, но там не так много доменов…
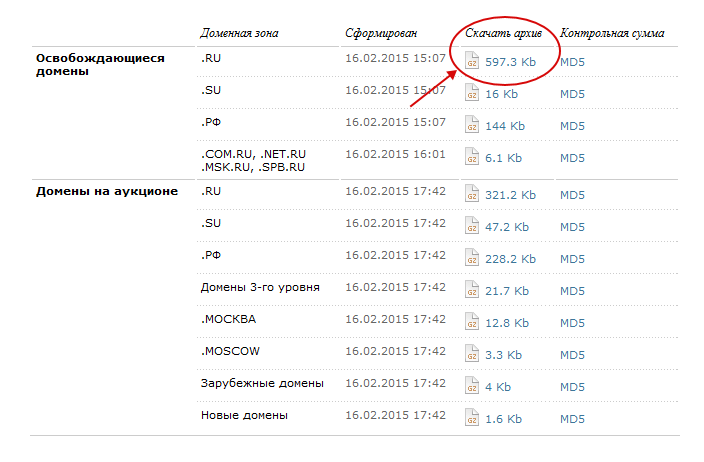
Полученный файл открываем с помощью Excel и жмем «ctrl+F», в поиске вводим ключевое слово, в моем примере это «Forex».
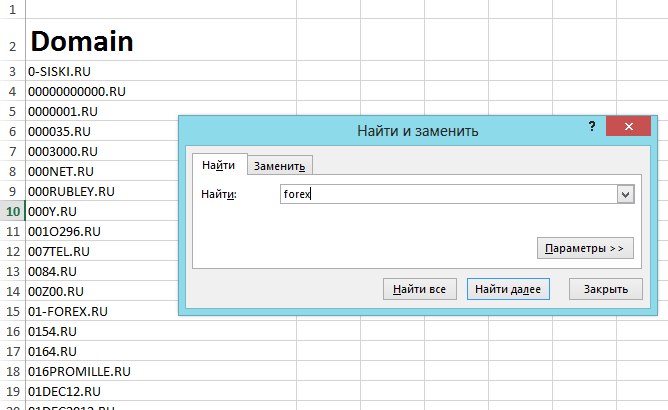
Нажали «найти все» и перед нами появился список нужных ячеек
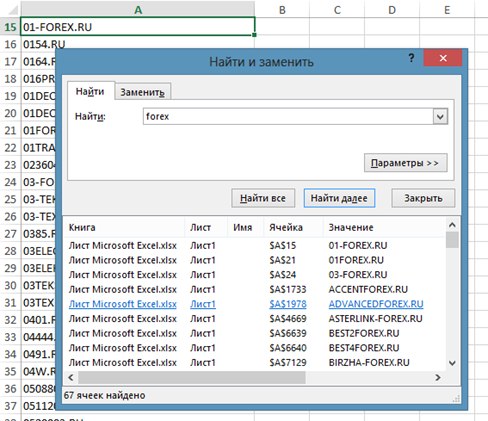
Теперь нужно получить из этого списка сайты в архиве.
Первый вариант — бесплатный сервис, проверяет только 30 ссылок за раз

Но этого вполне хватает, ведь по вашей теме не будет слишком много доменов, да и можно проверять пачками.
Второй вариант, это купить недорогую прогу, которая проверяет по 2000 ссылок за пару минут. Купить можно на форуме.
Вот и все, найденные страницы в вебархиве, через сервис или программу, мы мониторим уже глазками и ищем в куче файлов страницу со статьями или главную. Обязательно проверяйте домен на работоспособность, так как владельцы могли уже успеть продлить его.
Сервис показывает количество документов в вебархиве, цифры ниже 10 нас не интересуют. Старайтесь проверять как можно бОльшие цифры. К примеру, недавно я нашел сайт в вебархиве, нужной мне тематики, с 22000 документов, ох я и накопал оттуда хороших статеек!
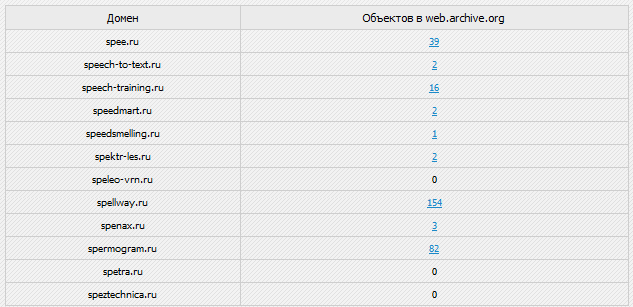
Вот так выглядят файлы в вебархиве.
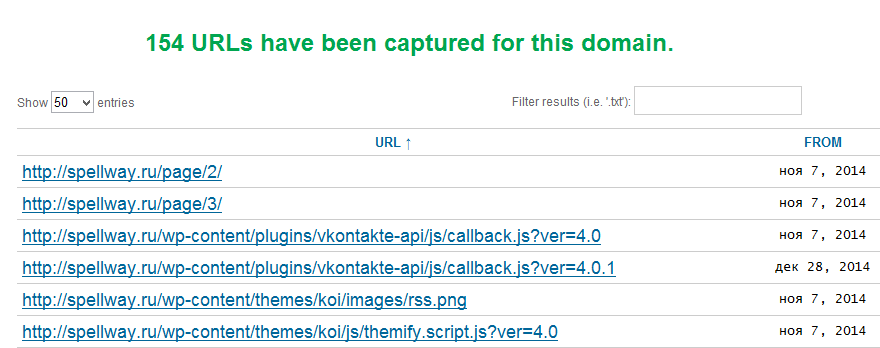
Стараемся попасть на сайте на главную страницу или найти карту сайта. Далее методично открываем статьи и проверяем их на уникальность. Я делаю это антиплагиатором от eTXT.
Второй способ, которым ищу именно я. Суть остается прежней, просто я беру домены ТУТ.
Самый жирный плюс этого сервиса в том, что мы можем пройтись по разным датам, а не качать домены освобождающиеся только в один день. Чем дальше по датам мы уходим, тем больше вероятность того, что домены не продлили.
В это сервисе все проще — выбираем дату, жмем Ctrl+A — копируем все что есть на странице и вставляем в NotePad++, так же жмем Ctrl+F и вводим нужный нам ключ и жмем — Найти ВСЕ в текущем документе.
После поиска это выглядит так:
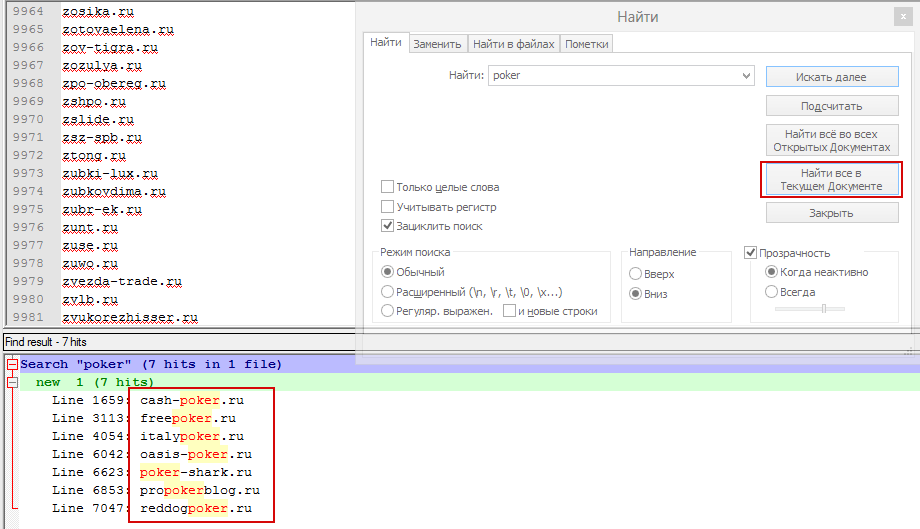
Вот и все =) Советую вам не париться с эксель и работать в нотпаде, а так же юзать сервис доменов по датам. Данным способом я нашел больше сотни отличных и уникальных статей на нужную мне тематику. На эти статьи, если бы я их заказал, у меня бы ушла не одна тысяча рублей… Всем благ и большого профита!
Большое спасибо за «тему». Ушло в закладки.
вебархив блочит. надо чистить кэш.менять айпи. что успел проверить, домены на самом деле большинство продлены.
Народ даже спец софтом мало что может оттуда вытянуть. Ибо тема заезжана уже давно.
Не знаю кто спец софтом не может вытянуть, я ручками за несколько дней достал 100+ отличных уникальных статей на дорогую тематику! Можете не пробовать, я не заставляю никого 😉
А как к такому контенту относятся ПС? Вот примером создать сдл…
Да отлично относится. Ведь ПС не хранит все тексты где-то, откуда ПС знать, что текст, когда-то уже был… Проверьте антиплагиаторами, если они показывают уник, значит и для ПС это новый и уникальный текст.
А как из блокнота скопировать, что бы не было номеров строк
Так в блокноте нет номеров сторк ) Да и в нотпаде эти строки никак не копируются
Ещё как хранит. Проверяйте в Etxt Антиплагиат
ля ПС это новый и уникальный текст.
Специально для манеймэкеров я откопал в интернете наш аналог вебархива . Там правда только ру зона и сайтов меньше — но домены зато на которых эти сайты раньше размещались, в настоящий момент свободные. Но есть и свои плюсы: качество копий лучше, сохранен флэш, картинки, навигация по страницам и ненадо мучится с кучей файлов.
Кстати в сети есть сайт, адрес правда не помню, он за небольшую плату даёт выкачивать страницы с оригинального вебархива, но там такая каша получается.
А поповоду уникальности — адвего плагиатус вам в помощь.
http://sitedrop.info/archive
ссылка на архив брошенных сайтов к коментарию выше.
p/s уважаемый админ этого сайта, вы хоть напишите что из тела сообщения ссылки трутся. Спасибо
Пользуясь сервисом domcop нахожу дропы. Смотрю по вебархиву, проверяю их на text.ru — контент не уник. Проверял кучу сайтов. Можно канибудб процесс автоматизировать?
Спасибо за статью. Не думал что так можно.
Сорян за некропостинг, но вдруг тема еще жива и интересна) Сейчас делаю автоматизатор для вебархива, вдруг будет интересным кому-то. Ща пока первая часть — беру свежие дроп-домены и ищу их в архиве.
Михаил, а напишите мне на почту что у вас получается [email protected] мне пригодится
Мои статьи пытались вытащить из вебархива. Но не учли, что есть такое понятие «авторское право». Эти статьи со своего брошенного сайта я планировала позже разместить на другом своем сайте. И тут какой-то чувак публикует их в сети. Дескать, а че такова??? Я же из «вебархива». В результате получил жалобу в яндекс на нарушение моих авторских прав, жалобу в гугл и жалобу на его хостинг. Не с первой попытки, но до него дошло.
Мораль: если статьи написаны не вами или не куплены вами, то пусть они хоть сто раз находятся в вебархивах, авторские права сохраняются за автором. Прикиньте? И если вы попадетесь на такую дотошную ковырялку как я, то нервов за публикацию чужого контента потратите массу.
Ахахаха
иди лапшу в другом месте вешай….
За свои слова (фараон говорил что он богом является) проклятый фараон уже страдает и будет страдать вечность. Это история Моисея и фараона описана в Коране в последнем Священном Писании.